
There are 3 different APIs for model evaluation:
1. Estimator score method: Estimator/model object has a ‘score()’ method that provides a default evaluation
2. Scoring parameter: Predefined scoring parameter that can be passed into cross_val_score() method
3. Metric function: Functions defined in the metrics module
Classification accuracy is an example of Scoring parameter API.
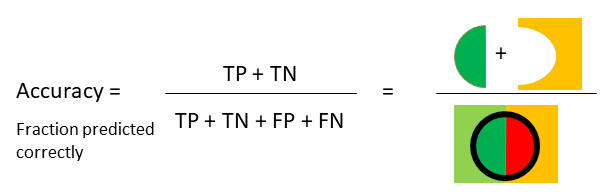
It is the most common metric for classification is accuracy, which is the number of correct predictions divided by total predictions.
Note:
– For the classification problem, we will use the Pima Indians onset of diabetes dataset.
– Estimator/Algorithm: Logistic Regression
– Cross-Validation Split: K-Fold (k=10)
- Load data/file from github
- Split columns into the usual feature columns(X) and target column(Y)
- Set k-fold count to 10
- Set seed to reproduce the same random data each time
- Split data using KFold() class
- Instantiate a classification model (LogisticRegression)
- Set scoring parameter to ‘accuracy’
- Call cross_val_score() to run cross validation
- Calculate mean and standard deviation from scores returned by cross_val_score()
# import modules
import pandas as pd
import numpy as np
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import train_test_split
# read data file from github
# dataframe: pimaDf
gitFileURL = 'https://raw.githubusercontent.com/andrewgurung/data-repository/master/pima-indians-diabetes.data.csv'
cols = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
pimaDf = pd.read_csv(gitFileURL, names = cols)
# convert into numpy array for scikit-learn
pimaArr = pimaDf.values
# Let's split columns into the usual feature columns(X) and target column(Y)
# Y represents the target 'class' column whose value is either '0' or '1'
X = pimaArr[:, 0:8]
Y = pimaArr[:, 8]
# set k-fold count
folds = 10
# set seed to reproduce the same random data each time
seed = 7
# split data using KFold
kfold = KFold(n_splits=folds, random_state=seed)
# instantiate a classification model
model = LogisticRegression()
# set scoring parameter to 'accuracy'
scoring = 'accuracy'
# call cross_val_score() to run cross validation
resultArr = cross_val_score(model, X, Y, cv=kfold, scoring=scoring)
# calculate mean of scores for all folds
meanAccuracy = resultArr.mean() * 100
# calculate standard deviation of scores for all folds
stdAccuracy = resultArr.std() * 100
# display accuracy
print("Mean accuracy: %.3f%%, Standard deviation: %.3f%%" % (meanAccuracy, stdAccuracy))
Mean accuracy: 76.951%, Standard deviation: 4.841%